Engineering Windows 7
Welcome to blog dedicated to the engineering of Microsoft Windows 7
What they did with a bug report?
This has been a busy couple of days for a few of us on the team as we had a report of a bug in Windows 7. The specifics of the issue are probably not as important as a discussion over how we will manage these types of situations down the road and so it seems like a good time to provide some context and illustrate our process, using this recent example.
This week a report on a blog described a crashing issue in Windows 7. The steps to reproduce the crash were pretty easy (1) run chkdsk /r on a non-system drive then crash after consuming system memory. Because it was easy to “reproduce”, the reports of this issue spread quickly. Subsequent posts and the comments across the posts indicated that the issue seemed to have been reproduced by others—that is the two characteristics of the report were seen (a) consumption of lots of memory and (b) crashing.
Pretty quickly, I started getting a lot of mail personally on the report. Like many of you, the first thing I did was try it out. And as you might imagine I did not reproduce both issues, though I did see the memory usage. I tried it on another machine and saw the same behavior. In both cases the machine functioned normally during and after the chkdsk. As I frequently do, I answered most of the mail I receive and started asking people for steps to reproduce the crash and to share system dump files. The memory usage did not worry me quite as much as the crash. I began having a number of interesting mail threads, but we didn’t have any leads on a repro case nor did we have a crash dump to work with.
Of course I was not the first Microsoft person to see this. The file system team immediately began to look into the issue. They too were unable to reproduce the crash and from their perspective the memory usage was by design and was a specific Windows 7 change for this scenario (the /r flag grabs an exclusive lock and repairs a disk and so our assumption is you’d really like the disk to be fixed before you do more stuff on the machine, an assumption validated by several subsequent third party blog posts on this topic). We cast the net further and continued looking for crash dumps and reports. As described below we have quite a few tools at our disposal.
While we continued to investigate, the mail I was getting was escalating in tone and more importantly one of the people I responded to mentioned our email exchange in a blog post. So in my effort to have a normal email dialog I ended up in the thick of the discussion. As I have done quite routinely during the development of Windows 7, I added a comment on the original blog (and the blog where this particular email friend was commenting) outlining the steps we are taking and the information we knew to date. Interestingly (though not unfortunately) just posting the comment drew even more attention to the issue being raised. I personally love being a member of the broader community and enjoy being a casual contributor even when it seems to cause a bit of a stir.
It is worth just describing the internal process that goes on when we receive a report of a crashing issue. Years ago we had one of two reactions. Either we would just throw up our arms and surrender as we had no hope of finding the bug, or we would drop everything and start putting people on airplanes with terminal debuggers in the hopes of finding a reproducible case. Neither of these is particularly effective and the latter, while very heroic sounding, does not yield results commensurate with effort. Most importantly while there might be a crash, we had no idea if that was the only instance or if lots more people were seeing or would see the crash. We were working without any data to inform our decisions.
With the internet and telemetry built into our products (not just Windows 7) we now have a much clearer view of the overall health of the software. So when we first hear a report of a crash we check to see if we’re seeing the crash happen on the millions of machines that are out there. This helps us in aggregate, but of course does not help us if a crash is one specific configuration. However, a crash that is one specific configuration will still show up if there is any statistically relevant sampling of machines and given the size of the user base this is almost certain to be the case. We’re able to, for example, query the call stacks of all crashes reported to see if a particular program is on the stack.
We have a number of tools at our disposal if we are seeing a crash in telemetry. You might have even seen these at work if you crash. We can increase (with consent) the amount of data asked for. We can put up a knowledge base article as a response to a crash (and you are notified in the Windows 7 Action Center). We can even say “hey call us”. As crazy as that one might sound, sometimes that is what can help. If a crashing issue in an already shipping product suddenly appears then something changed—a new hardware device, new device driver, or other software likely caused the crash to appear far more frequently. Often a simple confirmation of what changed helps us to diagnose the issue. I remember one of the first times we saw this was when one day unexpectedly Word started crashing for people. We hadn’t changed anything. It turned out a new version of a popular add-in released and the crash was happening in the add-in, but of course end-users only saw Word crashing. We quickly put up instructions to remove the add-in while in parallel working with the ISV to push out a fix. This ability to see the changing landscape, diagnose, and respond to a problem has radically changed how we think of issues in the product.
We are constantly investigating both new and frequently occurring issues (including crashes, hangs, device not found, setup failures, potential security issues, and so on). In fact we probably look into on the order of hundreds of issues in any given month as we work with our enterprise and OEM customers (and therefore hardware partners, ISVs, etc.). Often we find that issues are resolved by code changes outside core Windows code (such as with drivers, firmware, or ISV code). This isn’t about dodging responsibility but helping to fix things at the root cause. And we also make many code changes in Windows, which are seen as monthly updates, hotfixes, and then service pack rollups. The vast majority of things we fix are not applicable broadly and hence not released with immediate urgency—if something is ever broadly applicable we will make the call to release it broadly. It is very important for everyone to understand how seriously we take the responsibility of making sure there are no critical issues impacting a broad set of customers, while also balancing the volume of changes we push out broadly.
To be specific about the investigation around the chkdsk utility, let’s look at how we dove into this over the past couple of days. We first looked through our crash telemetry (both at the user level and “blue screen” level) and found no reported crashes of chkdsk. We of course look through our existing reports of issues that came up during the development of Windows 7, but we didn’t see anything at all there. We queried the call stacks of existing reported crashes (of all kinds, since this was reported) and we did not find any crashes with chkdsk.exe running while crashing. We then began automated test runs on a broad set of machines—these ran overnight and continued for 2 days. We also saw reports related to a specific hardware configuration, so we set up over 40 machines based on variants of that chipset, driver, and firmware and ran those tests. We were not hitting any crashes (as mentioned, the memory usage was already understood). Because some were saying the machines were non-responsive we also looked for that in manual tests and didn’t see anything. We also broadened this to request globally to Microsoft folks to try things out (we have quite a few unique configs when you think of all of our offices around the world) and so we had several hundred more test runs going. We also had reports of the crash happening when running without a pagefile—that could be the case, but that would not be an issue with this utility as any program that requests more memory than physically available would cause things to tip over and this configuration is not recommended for general purpose use (and this appears to be the common thread on the small number of non-reproducible crashes). Folks interested might read Mark’s blog on the topic of pagefiles in general. While we did not identify anything of note, that does not rule out the possibility of a problem but at this point the chances of any broad issue are extremely small.
In the meantime, we continue to look through external blogs, forums and other reports of crashes to see if we can identify any reproducible cases of this. While we don’t contact everyone, we do contact people if the forum and report indicate this has a good chance of yield. In all fairness, it probably doesn’t help us when there’s a lot of “smoke” while we’re trying to find the fire. We had a lot of “showstopper” comments piling on but not a lot of additional data including a lack of a reproducible case or a crash dump.
This type of work will continue until we have satisfied ourselves that we have systematically ruled out a crash or defined the circumstances where a crash can happen. Because this is a hardware/software related issue we will also invite input from various IHVs on the topic. In this case, because it is disk related we can’t rule out the possibility that in fact the disk was either failing or about to fail and the excessive use of the disk during a /r repair would in fact generate a failure. And while the code is designed to handle these failures (as you can imagine) there is the possibility that the specific failure is itself not handled well. In fact, in our lab (running tests continuously for a few days) we had one failure in this regard and the crash was in the firmware of the controller for the disk. Obviously we’ll continue to investigate this particular issue.
I did want folks to know just how seriously we take these issues. Sometimes blogs and comments get very excited. When I see something like “showstopper” it gets my attention, but it also doesn’t help us to have a constructive and rational investigation. Large software projects are by nature extremely complex. They often have issues that are dependent on the environment and configuration. And as we know, often as deterministic as software is supposed to be sometimes issues don’t reproduce. We have a pretty clear process on how we investigate reports and we focus on making sure Windows remains healthy even in the face of a changing landscape. With this post, I wanted to offer a view into some specifics but also into the general issue of sounding alarms.
It is always cool to find a bug in software. Whether it is an ATM, movie ticket machine, or Windows we all feel a certain sense of pride in identifying something that doesn’t work like we think it should. Windows is a product of a lot of people, not just those of us at Microsoft. When something isn’t as it should be we work with a broad set of partners to make sure we can effectively work through the issue. I hope folks recognize how serious we take this responsibility as we all know we’re going to keep looking at issues and we will have issues in the future that will require us to change the code to maintain the level of quality we know everyone expects of Windows.
We gather one last time (for Windows 7) in the “Ship Room” and a representative from each team signs (literally) and signifies their team’s readiness for manufacturing. We thought we’d share this moment with you here today.
On behalf of the Windows 7 engineering team we want to thank you very much for your contributions throughout development and your contributions yet to come to Windows 7. THANK YOU!
Next stop, October 22, 2009!
--The Windows 7 team
Posted by e7blog | 55 Comments
Filed under: Team
Tuesday, July 07, 2009 12:00 AM
Monday, August 31, 2009
Saturday, August 29, 2009
Windows 7 Know How---MUST VISIT

Extend Activation period to 120 days
Would you like to extend the activation period to the maximum 120 days instead of the 30 day period that is set by default? It is possible and legal to do this using the software licensing manager in Windows Vista and Windows 7. Simply run slmgr -rearm to get another 30 days at an administrative level command prompt. You can do this a maximum of three times before Microsoft blocks further extensions. Click on the Start Button and type in Command. The Command Prompt Prompt shortcut will now show up in your start panel search results. Right click on the shortcut and select Run as Administrator. After Command Prompt loads, type in slmgr.vbs -rearm and hit Enter. Reboot. ============================================================
Fine Tune ClearType Font Smoothing Everyone has a different idea of good font smoothing. What is nice and smooth to you may be blurry to someone else. That is why Microsoft included the ClearType Text Tuner in Windows 7. Start the ClearType Text Tuner by clicking on the Start Button and typing in cttune and then hit Enter.




{kind=link}
Customize Windows7 Your Own Way
Automatic Location Based Default Printer Switching
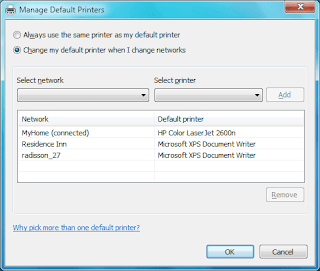
One of the most useful features of Windows 7 for business laptop users is automatic default printer switching based on location. In past versions of Windows it was only possible to have one default printer. In Window 7, you can set default printers based on location. For example, when you are at work your default printer is set to the big multi-function network printer but when you go home your default printer is automatically switched to your local ink jet printer. Automatic default printer switching monitors your computer for network connection changes and uses its database of printers to switch your printer. Printers and their corresponding network have to manually configured on the Manage default printers screen:
To configure automatic printer click on the Start Menu and type in Devices and Printers and hit Enter
Then, select one of your printers with your mouse.
Click the Manage default printers button on the toolbar.
Make sure Change my default printer when I change networks is selected. Then, select the network from the drop down list and then select the printer you want to use on that connection. When finished hit Add.
When you have finished setting up all of your default printers click OK to save your changes
You will now have an shortcut on the desktop that will launch Flip3D but it has the wrong icon.
One of the most useful features of Windows 7 for business laptop users is automatic default printer switching based on location. In past versions of Windows it was only possible to have one default printer. In Window 7, you can set default printers based on location. For example, when you are at work your default printer is set to the big multi-function network printer but when you go home your default printer is automatically switched to your local ink jet printer. Automatic default printer switching monitors your computer for network connection changes and uses its database of printers to switch your printer. Printers and their corresponding network have to manually configured on the Manage default printers screen:



To configure automatic printer click on the Start Menu and type in Devices and Printers and hit Enter
Then, select one of your printers with your mouse.
Click the Manage default printers button on the toolbar.
Make sure Change my default printer when I change networks is selected. Then, select the network from the drop down list and then select the printer you want to use on that connection. When finished hit Add.
When you have finished setting up all of your default printers click OK to save your changes
================================================================
Bypass open with lookup web service
When opening up a file in windows that does not already have a registered file association you are prompted if you would like to specify what file to use to open the file or if you would like to use a web service. The web service is a great idea for the average computer user but for advanced users, you likely already know what you want to open the file with.
With the help of a registry change you can disable the web service lookup and bypass that screen entirely. Instead you will be taken directly to the list of applications on your computer you can open the file with.
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\Explorer]
NoInternetOpenWith
Create a DWORD called NoInternetOpenWith and set it to 1.
The next time you use Open With on a file you will be taken directly to the application list.
When opening up a file in windows that does not already have a registered file association you are prompted if you would like to specify what file to use to open the file or if you would like to use a web service. The web service is a great idea for the average computer user but for advanced users, you likely already know what you want to open the file with.
With the help of a registry change you can disable the web service lookup and bypass that screen entirely. Instead you will be taken directly to the list of applications on your computer you can open the file with.
[HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\Explorer]
NoInternetOpenWith
Create a DWORD called NoInternetOpenWith and set it to 1.
The next time you use Open With on a file you will be taken directly to the application list.
==============================================================
Windows 7 includes a new tool to help you calibrate the correct gamma, contrast, brightness and color settings for your specific display.
Just click on the Start Button and type in dccw and hit Enter.
Then follow the on screen directions and adjust the sliders..
Just click on the Start Button and type in dccw and hit Enter.
Then follow the on screen directions and adjust the sliders..
================================================================
Change Windows Product Key After Install
Do you need to change your product key so you can activate Windows Vista or Windows 7 properly? You can use a great command line tool that will help you do this very easily. Just follow these steps:
Click on the Start Button and type in command prompt so that it shows up on your start menu search list. Right click on the Command Prompt shortcut and select Run As Administrator.
At the administrator command prompt, type in "slmgr.vbs -ipk"
To activate windows after changing the key, run "slmgr.vbs -ato"
Do you need to change your product key so you can activate Windows Vista or Windows 7 properly? You can use a great command line tool that will help you do this very easily. Just follow these steps:
Click on the Start Button and type in command prompt so that it shows up on your start menu search list. Right click on the Command Prompt shortcut and select Run As Administrator.
At the administrator command prompt, type in "slmgr.vbs -ipk
To activate windows after changing the key, run "slmgr.vbs -ato"
=======================================================================
Create a Flip3D Taskbar Icon in Windows 7
Flip3D was a fun and cool looking feature in Windows Vista that can be very useful for switching between windows. With the improved Windows 7 taskbar, Flip3D was replaced with improved thumbnails and Aero Peek. Those are both good alternatives but I like the speed of viewing all my open windows at once and switching with just two clicks.
This article will show you how to create a Flip3D icon on the Windows 7 taskbar:
Right click on the Desktop and select New and then Shortcut.
Type in RunDll32 DwmApi #105 in the location box and click Next.
Type in Flip3D as the Name and click Finish.
Flip3D was a fun and cool looking feature in Windows Vista that can be very useful for switching between windows. With the improved Windows 7 taskbar, Flip3D was replaced with improved thumbnails and Aero Peek. Those are both good alternatives but I like the speed of viewing all my open windows at once and switching with just two clicks.
This article will show you how to create a Flip3D icon on the Windows 7 taskbar:
Right click on the Desktop and select New and then Shortcut.
Type in RunDll32 DwmApi #105 in the location box and click Next.
Type in Flip3D as the Name and click Finish.
You will now have an shortcut on the desktop that will launch Flip3D but it has the wrong icon.
Right click on the Flip3D shortcut and select Properties.
On the Shortcut tab click the Change Icon button.
Change the Look for icons in this file text box to C:\windows\explorer.exe and it Enter. The Flip3D icon will now be available. Select it and click OK.
Click OK to close out the shortcut properties window.
Finally, just drag and drop the new shortcut on the Windows 7 taskbar to pin it.
On the Shortcut tab click the Change Icon button.
Change the Look for icons in this file text box to C:\windows\explorer.exe and it Enter. The Flip3D icon will now be available. Select it and click OK.
Click OK to close out the shortcut properties window.
Finally, just drag and drop the new shortcut on the Windows 7 taskbar to pin it.
============================================================
Create a System Repair/Recovery Disc
New in Windows 7 is the ability to create a system repair CD that will help you recover your computer from serious errors preventing windows from starting up. The recovery disc is based on Windows PE and includes the standard recovery options that are found on any Windows 7 installation disc.
If you have a Windows 7 installation disc, that doubles as a repair disc so you don’t need another. This article is only useful for users that have Windows 7 pre-installed and did not receive the installation media with their computer.
Creating the disc is very simple. Just click on the start button and type in recdisc.exe and press Enter
If you have a Windows 7 installation disc, that doubles as a repair disc so you don’t need another. This article is only useful for users that have Windows 7 pre-installed and did not receive the installation media with their computer.
Creating the disc is very simple. Just click on the start button and type in recdisc.exe and press Enter
Once started, put in a CD-R or CD-RW into your burner and click Start Burning.
============================================================
Friday, August 28, 2009
SQL INJECTION
SQL Injection Attacks by Example
A customer asked that we check out his intranet site, which was used by the company's employees and customers. This was part of a larger security review, and though we'd not actually used SQL injection to penetrate a network before, we were pretty familiar with the general concepts. We were completely successful in this engagement, and wanted to recount the steps taken as an illustration.
Table of Contents
The Target Intranet
Schema field mapping
Finding the table name
Finding some users
Brute-force password guessing
The database isn't readonly
Adding a new member
Mail me a password
Other approaches
Mitigations
Other resources
"SQL Injection" is subset of the an unverified/unsanitized user input vulnerability ("buffer overflows" are a different subset), and the idea is to convince the application to run SQL code that was not intended. If the application is creating SQL strings naively on the fly and then running them, it's straightforward to create some real surprises.
We'll note that this was a somewhat winding road with more than one wrong turn, and others with more experience will certainly have different -- and better -- approaches. But the fact that we were successful does suggest that we were not entirely misguided.
There have been other papers on SQL injection, including some that are much more detailed, but this one shows the rationale of discovery as much as the process of exploitation.
The Target Intranet
This appeared to be an entirely custom application, and we had no prior knowledge of the application nor access to the source code: this was a "blind" attack. A bit of poking showed that this server ran Microsoft's IIS 6 along with ASP.NET, and this suggested that the database was Microsoft's SQL server: we believe that these techniques can apply to nearly any web application backed by any SQL server.
The login page had a traditional username-and-password form, but also an email-me-my-password link; the latter proved to be the downfall of the whole system.
When entering an email address, the system presumably looked in the user database for that email address, and mailed something to that address. Since my email address is not found, it wasn't going to send me anything.
So the first test in any SQL-ish form is to enter a single quote as part of the data: the intention is to see if they construct an SQL string literally without sanitizing. When submitting the form with a quote in the email address, we get a 500 error (server failure), and this suggests that the "broken" input is actually being parsed literally. Bingo.
We speculate that the underlying SQL code looks something like this: SELECT fieldlist
FROM table
WHERE field = '$EMAIL';
Here, $EMAIL is the address submitted on the form by the user, and the larger query provides the quotation marks that set it off as a literal string. We don't know the specific names of the fields or table involved, but we do know their nature, and we'll make some good guesses later.
When we enter steve@unixwiz.net' - note the closing quote mark - this yields constructed SQL: SELECT fieldlist
FROM table
WHERE field = 'steve@unixwiz.net'';
when this is executed, the SQL parser find the extra quote mark and aborts with a syntax error. How this manifests itself to the user depends on the application's internal error-recovery procedures, but it's usually different from "email address is unknown". This error response is a dead giveaway that user input is not being sanitized properly and that the application is ripe for exploitation.
Since the data we're filling in appears to be in the WHERE clause, let's change the nature of that clause in an SQL legal way and see what happens. By entering anything' OR 'x'='x, the resulting SQL is: SELECT fieldlist
FROM table
WHERE field = 'anything' OR 'x'='x';
Because the application is not really thinking about the query - merely constructing a string - our use of quotes has turned a single-component WHERE clause into a two-component one, and the 'x'='x' clause is guaranteed to be true no matter what the first clause is (there is a better approach for this "always true" part that we'll touch on later).
But unlike the "real" query, which should return only a single item each time, this version will essentially return every item in the members database. The only way to find out what the application will do in this circumstance is to try it. Doing so, we were greeted with:
Your login information has been mailed to random.person@example.com.
Our best guess is that it's the first record returned by the query, effectively an entry taken at random. This person really did get this forgotten-password link via email, which will probably come as surprise to him and may raise warning flags somewhere.
We now know that we're able to manipulate the query to our own ends, though we still don't know much about the parts of it we cannot see. But we have observed three different responses to our various inputs:
"Your login information has been mailed to email"
"We don't recognize your email address"
Server error
The first two are responses to well-formed SQL, while the latter is for bad SQL: this distinction will be very useful when trying to guess the structure of the query.
Schema field mapping
The first steps are to guess some field names: we're reasonably sure that the query includes "email address" and "password", and there may be things like "US Mail address" or "userid" or "phone number". We'd dearly love to perform a SHOW TABLE, but in addition to not knowing the name of the table, there is no obvious vehicle to get the output of this command routed to us.
So we'll do it in steps. In each case, we'll show the whole query as we know it, with our own snippets shown specially. We know that the tail end of the query is a comparison with the email address, so let's guess email as the name of the field: SELECT fieldlist
FROM table
WHERE field = 'x' AND email IS NULL; --';
The intent is to use a proposed field name (email) in the constructed query and find out if the SQL is valid or not. We don't care about matching the email address (which is why we use a dummy 'x'), and the -- marks the start of an SQL comment. This is an effective way to "consume" the final quote provided by application and not worry about matching them.
If we get a server error, it means our SQL is malformed and a syntax error was thrown: it's most likely due to a bad field name. If we get any kind of valid response, we guessed the name correctly. This is the case whether we get the "email unknown" or "password was sent" response.
Note, however, that we use the AND conjunction instead of OR: this is intentional. In the SQL schema mapping phase, we're not really concerned with guessing any particular email addresses, and we do not want random users inundated with "here is your password" emails from the application - this will surely raise suspicions to no good purpose. By using the AND conjunction with an email address that couldn't ever be valid, we're sure that the query will always return zero rows and never generate a password-reminder email.
Submitting the above snippet indeed gave us the "email address unknown" response, so now we know that the email address is stored in a field email. If this hadn't worked, we'd have tried email_address or mail or the like. This process will involve quite a lot of guessing.
Next we'll guess some other obvious names: password, user ID, name, and the like. These are all done one at a time, and anything other than "server failure" means we guessed the name correctly. SELECT fieldlist
FROM table
WHERE email = 'x' AND userid IS NULL; --';
As a result of this process, we found several valid field names:
email
passwd
login_id
full_name
There are certainly more (and a good source of clues is the names of the fields on forms), but a bit of digging did not discover any. But we still don't know the name of the table that these fields are found in - how to find out?
Finding the table name
The application's built-in query already has the table name built into it, but we don't know what that name is: there are several approaches for finding that (and other) table names. The one we took was to rely on a subselect.
A standalone query of SELECT COUNT(*) FROM tabname
Returns the number of records in that table, and of course fails if the table name is unknown. We can build this into our string to probe for the table name: SELECT email, passwd, login_id, full_name
FROM table
WHERE email = 'x' AND 1=(SELECT COUNT(*) FROM tabname); --';
We don't care how many records are there, of course, only whether the table name is valid or not. By iterating over several guesses, we eventually determined that members was a valid table in the database. But is it the table used in this query? For that we need yet another test using table.field notation: it only works for tables that are actually part of this query, not merely that the table exists. SELECT email, passwd, login_id, full_name
FROM members
WHERE email = 'x' AND members.email IS NULL; --';
When this returned "Email unknown", it confirmed that our SQL was well formed and that we had properly guessed the table name. This will be important later, but we instead took a different approach in the interim.
Finding some users
At this point we have a partial idea of the structure of the members table, but we only know of one username: the random member who got our initial "Here is your password" email. Recall that we never received the message itself, only the address it was sent to. We'd like to get some more names to work with, preferably those likely to have access to more data.
The first place to start, of course, is the company's website to find who is who: the "About us" or "Contact" pages often list who's running the place. Many of these contain email addresses, but even those that don't list them can give us some clues which allow us to find them with our tool.
The idea is to submit a query that uses the LIKE clause, allowing us to do partial matches of names or email addresses in the database, each time triggering the "We sent your password" message and email. Warning: though this reveals an email address each time we run it, it also actually sends that email, which may raise suspicions. This suggests that we take it easy.
We can do the query on email name or full name (or presumably other information), each time putting in the % wildcards that LIKE supports: SELECT email, passwd, login_id, full_name
FROM members
WHERE email = 'x' OR full_name LIKE '%Bob%';
Keep in mind that even though there may be more than one "Bob", we only get to see one of them: this suggests refining our LIKE clause narrowly.
Ultimately, we may only need one valid email address to leverage our way in.
Brute-force password guessing
One can certainly attempt brute-force guessing of passwords at the main login page, but many systems make an effort to detect or even prevent this. There could be logfiles, account lockouts, or other devices that would substantially impede our efforts, but because of the non-sanitized inputs, we have another avenue that is much less likely to be so protected.
We'll instead do actual password testing in our snippet by including the email name and password directly. In our example, we'll use our victim, bob@example.com and try multiple passwords. SELECT email, passwd, login_id, full_name
FROM members
WHERE email = 'bob@example.com' AND passwd = 'hello123';
This is clearly well-formed SQL, so we don't expect to see any server errors, and we'll know we found the password when we receive the "your password has been mailed to you" message. Our mark has now been tipped off, but we do have his password.
This procedure can be automated with scripting in perl, and though we were in the process of creating this script, we ended up going down another road before actually trying it.
The database isn't readonly
So far, we have done nothing but query the database, and even though a SELECT is readonly, that doesn't mean that SQL is. SQL uses the semicolon for statement termination, and if the input is not sanitized properly, there may be nothing that prevents us from stringing our own unrelated command at the end of the query.
The most drastic example is: SELECT email, passwd, login_id, full_name
FROM members
WHERE email = 'x'; DROP TABLE members; --'; -- Boom!
The first part provides a dummy email address -- 'x' -- and we don't care what this query returns: we're just getting it out of the way so we can introduce an unrelated SQL command. This one attempts to drop (delete) the entire members table, which really doesn't seem too sporting.
This shows that not only can we run separate SQL commands, but we can also modify the database. This is promising.
Adding a new member
Given that we know the partial structure of the members table, it seems like a plausible approach to attempt adding a new record to that table: if this works, we'll simply be able to login directly with our newly-inserted credentials.
This, not surprisingly, takes a bit more SQL, and we've wrapped it over several lines for ease of presentation, but our part is still one contiguous string: SELECT email, passwd, login_id, full_name
FROM members
WHERE email = 'x';
INSERT INTO members ('email','passwd','login_id','full_name')
VALUES ('steve@unixwiz.net','hello','steve','Steve Friedl');--';
Even if we have actually gotten our field and table names right, several things could get in our way of a successful attack:
We might not have enough room in the web form to enter this much text directly (though this can be worked around via scripting, it's much less convenient).
The web application user might not have INSERT permission on the members table.
There are undoubtedly other fields in the members table, and some may require initial values, causing the INSERT to fail.
Even if we manage to insert a new record, the application itself might not behave well due to the auto-inserted NULL fields that we didn't provide values for.
A valid "member" might require not only a record in the members table, but associated information in other tables (say, "accessrights"), so adding to one table alone might not be sufficient.
In the case at hand, we hit a roadblock on either #4 or #5 - we can't really be sure -- because when going to the main login page and entering in the above username + password, a server error was returned. This suggests that fields we did not populate were vital, but nevertheless not handled properly.
A possible approach here is attempting to guess the other fields, but this promises to be a long and laborious process: though we may be able to guess other "obvious" fields, it's very hard to imagine the bigger-picture organization of this application.
We ended up going down a different road.
Mail me a password
We then realized that though we are not able to add a new record to the members database, we can modify an existing one, and this proved to be the approach that gained us entry.
From a previous step, we knew that bob@example.com had an account on the system, and we used our SQL injection to update his database record with our email address: SELECT email, passwd, login_id, full_name
FROM members
WHERE email = 'x';
UPDATE members
SET email = 'steve@unixwiz.net'
WHERE email = 'bob@example.com';
After running this, we of course received the "we didn't know your email address", but this was expected due to the dummy email address provided. The UPDATE wouldn't have registered with the application, so it executed quietly.
We then used the regular "I lost my password" link - with the updated email address - and a minute later received this email: From: system@example.com
To: steve@unixwiz.net
Subject: Intranet login
This email is in response to your request for your Intranet log in information.
Your User ID is: bob
Your password is: hello
Now it was now just a matter of following the standard login process to access the system as a high-ranked MIS staffer, and this was far superior to a perhaps-limited user that we might have created with our INSERT approach.
We found the intranet site to be quite comprehensive, and it included - among other things - a list of all the users. It's a fair bet that many Intranet sites also have accounts on the corporate Windows network, and perhaps some of them have used the same password in both places. Since it's clear that we have an easy way to retrieve any Intranet password, and since we had located an open PPTP VPN port on the corporate firewall, it should be straightforward to attempt this kind of access.
We had done a spot check on a few accounts without success, and we can't really know whether it's "bad password" or "the Intranet account name differs from the Windows account name". But we think that automated tools could make some of this easier.
Other Approaches
In this particular engagement, we obtained enough access that we did not feel the need to do much more, but other steps could have been taken. We'll touch on the ones that we can think of now, though we are quite certain that this is not comprehensive.
We are also aware that not all approaches work with all databases, and we can touch on some of them here.
Use xp_cmdshell
Microsoft's SQL Server supports a stored procedure xp_cmdshell that permits what amounts to arbitrary command execution, and if this is permitted to the web user, complete compromise of the webserver is inevitable.
What we had done so far was limited to the web application and the underlying database, but if we can run commands, the webserver itself cannot help but be compromised. Access to xp_cmdshell is usually limited to administrative accounts, but it's possible to grant it to lesser users.
Map out more database structure
Though this particular application provided such a rich post-login environment that it didn't really seem necessary to dig further, in other more limited environments this may not have been sufficient.
Being able to systematically map out the available schema, including tables and their field structure, can't help but provide more avenues for compromise of the application.
One could probably gather more hints about the structure from other aspects of the website (e.g., is there a "leave a comment" page? Are there "support forums"?). Clearly, this is highly dependent on the application and it relies very much on making good guesses.
Mitigations
We believe that web application developers often simply do not think about "surprise inputs", but security people do (including the bad guys), so there are three broad approaches that can be applied here.
Sanitize the input
It's absolutely vital to sanitize user inputs to insure that they do not contain dangerous codes, whether to the SQL server or to HTML itself. One's first idea is to strip out "bad stuff", such as quotes or semicolons or escapes, but this is a misguided attempt. Though it's easy to point out some dangerous characters, it's harder to point to all of them.
The language of the web is full of special characters and strange markup (including alternate ways of representing the same characters), and efforts to authoritatively identify all "bad stuff" are unlikely to be successful.
Instead, rather than "remove known bad data", it's better to "remove everything but known good data": this distinction is crucial. Since - in our example - an email address can contain only these characters:
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
0123456789
@.-_+
There is really no benefit in allowing characters that could not be valid, and rejecting them early - presumably with an error message - not only helps forestall SQL Injection, but also catches mere typos early rather than stores them into the database.
Sidebar on email addresses
It's important to note here that email addresses in particular are troublesome to validate programmatically, because everybody seems to have his own idea about what makes one "valid", and it's a shame to exclude a good email address because it contains a character you didn't think about.
The only real authority is RFC 2822 (which encompasses the more familiar RFC822), and it includes a fairly expansive definition of what's allowed. The truly pedantic may well wish to accept email addresses with ampersands and asterisks (among other things) as valid, but others - including this author - are satisfied with a reasonable subset that includes "most" email addresses.
Those taking a more restrictive approach ought to be fully aware of the consequences of excluding these addresses, especially considering that better techniques (prepare/execute, stored procedures) obviate the security concerns which those "odd" characters present.
Be aware that "sanitizing the input" doesn't mean merely "remove the quotes", because even "regular" characters can be troublesome. In an example where an integer ID value is being compared against the user input (say, a numeric PIN):
SELECT fieldlist
FROM table
WHERE id = 23 OR 1=1; -- Boom! Always matches!
In practice, however, this approach is highly limited because there are so few fields for which it's possible to outright exclude many of the dangerous characters. For "dates" or "email addresses" or "integers" it may have merit, but for any kind of real application, one simply cannot avoid the other mitigations.
Escape/Quotesafe the input
Even if one might be able to sanitize a phone number or email address, one cannot take this approach with a "name" field lest one wishes to exclude the likes of Bill O'Reilly from one's application: a quote is simply a valid character for this field.
One includes an actual single quote in an SQL string by putting two of them together, so this suggests the obvious - but wrong! - technique of preprocessing every string to replicate the single quotes:
SELECT fieldlist
FROM customers
WHERE name = 'Bill O''Reilly'; -- works OK
However, this naïve approach can be beaten because most databases support other string escape mechanisms. MySQL, for instance, also permits \' to escape a quote, so after input of \'; DROP TABLE users; -- is "protected" by doubling the quotes, we get:
SELECT fieldlist
FROM customers
WHERE name = '\''; DROP TABLE users; --'; -- Boom!
The expression '\'' is a complete string (containing just one single quote), and the usual SQL shenanigans follow. It doesn't stop with backslashes either: there is Unicode, other encodings, and parsing oddities all hiding in the weeds to trip up the application designer.
Getting quotes right is notoriously difficult, which is why many database interface languages provide a function that does it for you. When the same internal code is used for "string quoting" and "string parsing", it's much more likely that the process will be done properly and safely.
Some examples are the MySQL function mysql_real_escape_string() and perl DBD method $dbh->quote($value).
These methods must be used.
Use bound parameters (the PREPARE statement)
Though quotesafing is a good mechanism, we're still in the area of "considering user input as SQL", and a much better approach exists: bound parameters, which are supported by essentially all database programming interfaces. In this technique, an SQL statement string is created with placeholders - a question mark for each parameter - and it's compiled ("prepared", in SQL parlance) into an internal form.
Later, this prepared query is "executed" with a list of parameters:
Example in perl$sth = $dbh->prepare("SELECT email, userid FROM members WHERE email = ?;");
$sth->execute($email);
Thanks to Stefan Wagner, this demonstrates bound parameters in Java:
Insecure versionStatement s = connection.createStatement();
ResultSet rs = s.executeQuery("SELECT email FROM member WHERE name = "
+ formField); // *boom*
Secure versionPreparedStatement ps = connection.prepareStatement(
"SELECT email FROM member WHERE name = ?");
ps.setString(1, formField);
ResultSet rs = ps.executeQuery();
Here, $email is the data obtained from the user's form, and it is passed as positional parameter #1 (the first question mark), and at no point do the contents of this variable have anything to do with SQL statement parsing. Quotes, semicolons, backslashes, SQL comment notation - none of this has any impact, because it's "just data". There simply is nothing to subvert, so the application is be largely immune to SQL injection attacks.
There also may be some performance benefits if this prepared query is reused multiple times (it only has to be parsed once), but this is minor compared to the enormous security benefits. This is probably the single most important step one can take to secure a web application.
Limit database permissions and segregate users
In the case at hand, we observed just two interactions that are made not in the context of a logged-in user: "log in" and "send me password". The web application ought to use a database connection with the most limited rights possible: query-only access to the members table, and no access to any other table.
The effect here is that even a "successful" SQL injection attack is going to have much more limited success. Here, we'd not have been able to do the UPDATE request that ultimately granted us access, so we'd have had to resort to other avenues.
Once the web application determined that a set of valid credentials had been passed via the login form, it would then switch that session to a database connection with more rights.
It should go almost without saying that sa rights should never be used for any web-based application.
Use stored procedures for database access
When the database server supports them, use stored procedures for performing access on the application's behalf, which can eliminate SQL entirely (assuming the stored procedures themselves are written properly).
By encapsulating the rules for a certain action - query, update, delete, etc. - into a single procedure, it can be tested and documented on a standalone basis and business rules enforced (for instance, the "add new order" procedure might reject that order if the customer were over his credit limit).
For simple queries this might be only a minor benefit, but as the operations become more complicated (or are used in more than one place), having a single definition for the operation means it's going to be more robust and easier to maintain.
Note: it's always possible to write a stored procedure that itself constructs a query dynamically: this provides no protection against SQL Injection - it's only proper binding with prepare/execute or direct SQL statements with bound variables that provide this protection.
Isolate the webserver
Even having taken all these mitigation steps, it's nevertheless still possible to miss something and leave the server open to compromise. One ought to design the network infrastructure to assume that the bad guy will have full administrator access to the machine, and then attempt to limit how that can be leveraged to compromise other things.
For instance, putting the machine in a DMZ with extremely limited pinholes "inside" the network means that even getting complete control of the webserver doesn't automatically grant full access to everything else. This won't stop everything, of course, but it makes it a lot harder.
Configure error reporting
The default error reporting for some frameworks includes developer debugging information, and this cannot be shown to outside users. Imagine how much easier a time it makes for an attacker if the full query is shown, pointing to the syntax error involved.
This information is useful to developers, but it should be restricted - if possible - to just internal users.
Note that not all databases are configured the same way, and not all even support the same dialect of SQL (the "S" stands for "Structured", not "Standard"). For instance, most versions of MySQL do not support subselects, nor do they usually allow multiple statements: these are substantially complicating factors when attempting to penetrate a network.
A customer asked that we check out his intranet site, which was used by the company's employees and customers. This was part of a larger security review, and though we'd not actually used SQL injection to penetrate a network before, we were pretty familiar with the general concepts. We were completely successful in this engagement, and wanted to recount the steps taken as an illustration.
Table of Contents
The Target Intranet
Schema field mapping
Finding the table name
Finding some users
Brute-force password guessing
The database isn't readonly
Adding a new member
Mail me a password
Other approaches
Mitigations
Other resources
"SQL Injection" is subset of the an unverified/unsanitized user input vulnerability ("buffer overflows" are a different subset), and the idea is to convince the application to run SQL code that was not intended. If the application is creating SQL strings naively on the fly and then running them, it's straightforward to create some real surprises.
We'll note that this was a somewhat winding road with more than one wrong turn, and others with more experience will certainly have different -- and better -- approaches. But the fact that we were successful does suggest that we were not entirely misguided.
There have been other papers on SQL injection, including some that are much more detailed, but this one shows the rationale of discovery as much as the process of exploitation.
The Target Intranet
This appeared to be an entirely custom application, and we had no prior knowledge of the application nor access to the source code: this was a "blind" attack. A bit of poking showed that this server ran Microsoft's IIS 6 along with ASP.NET, and this suggested that the database was Microsoft's SQL server: we believe that these techniques can apply to nearly any web application backed by any SQL server.
The login page had a traditional username-and-password form, but also an email-me-my-password link; the latter proved to be the downfall of the whole system.
When entering an email address, the system presumably looked in the user database for that email address, and mailed something to that address. Since my email address is not found, it wasn't going to send me anything.
So the first test in any SQL-ish form is to enter a single quote as part of the data: the intention is to see if they construct an SQL string literally without sanitizing. When submitting the form with a quote in the email address, we get a 500 error (server failure), and this suggests that the "broken" input is actually being parsed literally. Bingo.
We speculate that the underlying SQL code looks something like this: SELECT fieldlist
FROM table
WHERE field = '$EMAIL';
Here, $EMAIL is the address submitted on the form by the user, and the larger query provides the quotation marks that set it off as a literal string. We don't know the specific names of the fields or table involved, but we do know their nature, and we'll make some good guesses later.
When we enter steve@unixwiz.net' - note the closing quote mark - this yields constructed SQL: SELECT fieldlist
FROM table
WHERE field = 'steve@unixwiz.net'';
when this is executed, the SQL parser find the extra quote mark and aborts with a syntax error. How this manifests itself to the user depends on the application's internal error-recovery procedures, but it's usually different from "email address is unknown". This error response is a dead giveaway that user input is not being sanitized properly and that the application is ripe for exploitation.
Since the data we're filling in appears to be in the WHERE clause, let's change the nature of that clause in an SQL legal way and see what happens. By entering anything' OR 'x'='x, the resulting SQL is: SELECT fieldlist
FROM table
WHERE field = 'anything' OR 'x'='x';
Because the application is not really thinking about the query - merely constructing a string - our use of quotes has turned a single-component WHERE clause into a two-component one, and the 'x'='x' clause is guaranteed to be true no matter what the first clause is (there is a better approach for this "always true" part that we'll touch on later).
But unlike the "real" query, which should return only a single item each time, this version will essentially return every item in the members database. The only way to find out what the application will do in this circumstance is to try it. Doing so, we were greeted with:
Your login information has been mailed to random.person@example.com.
Our best guess is that it's the first record returned by the query, effectively an entry taken at random. This person really did get this forgotten-password link via email, which will probably come as surprise to him and may raise warning flags somewhere.
We now know that we're able to manipulate the query to our own ends, though we still don't know much about the parts of it we cannot see. But we have observed three different responses to our various inputs:
"Your login information has been mailed to email"
"We don't recognize your email address"
Server error
The first two are responses to well-formed SQL, while the latter is for bad SQL: this distinction will be very useful when trying to guess the structure of the query.
Schema field mapping
The first steps are to guess some field names: we're reasonably sure that the query includes "email address" and "password", and there may be things like "US Mail address" or "userid" or "phone number". We'd dearly love to perform a SHOW TABLE, but in addition to not knowing the name of the table, there is no obvious vehicle to get the output of this command routed to us.
So we'll do it in steps. In each case, we'll show the whole query as we know it, with our own snippets shown specially. We know that the tail end of the query is a comparison with the email address, so let's guess email as the name of the field: SELECT fieldlist
FROM table
WHERE field = 'x' AND email IS NULL; --';
The intent is to use a proposed field name (email) in the constructed query and find out if the SQL is valid or not. We don't care about matching the email address (which is why we use a dummy 'x'), and the -- marks the start of an SQL comment. This is an effective way to "consume" the final quote provided by application and not worry about matching them.
If we get a server error, it means our SQL is malformed and a syntax error was thrown: it's most likely due to a bad field name. If we get any kind of valid response, we guessed the name correctly. This is the case whether we get the "email unknown" or "password was sent" response.
Note, however, that we use the AND conjunction instead of OR: this is intentional. In the SQL schema mapping phase, we're not really concerned with guessing any particular email addresses, and we do not want random users inundated with "here is your password" emails from the application - this will surely raise suspicions to no good purpose. By using the AND conjunction with an email address that couldn't ever be valid, we're sure that the query will always return zero rows and never generate a password-reminder email.
Submitting the above snippet indeed gave us the "email address unknown" response, so now we know that the email address is stored in a field email. If this hadn't worked, we'd have tried email_address or mail or the like. This process will involve quite a lot of guessing.
Next we'll guess some other obvious names: password, user ID, name, and the like. These are all done one at a time, and anything other than "server failure" means we guessed the name correctly. SELECT fieldlist
FROM table
WHERE email = 'x' AND userid IS NULL; --';
As a result of this process, we found several valid field names:
passwd
login_id
full_name
There are certainly more (and a good source of clues is the names of the fields on forms), but a bit of digging did not discover any. But we still don't know the name of the table that these fields are found in - how to find out?
Finding the table name
The application's built-in query already has the table name built into it, but we don't know what that name is: there are several approaches for finding that (and other) table names. The one we took was to rely on a subselect.
A standalone query of SELECT COUNT(*) FROM tabname
Returns the number of records in that table, and of course fails if the table name is unknown. We can build this into our string to probe for the table name: SELECT email, passwd, login_id, full_name
FROM table
WHERE email = 'x' AND 1=(SELECT COUNT(*) FROM tabname); --';
We don't care how many records are there, of course, only whether the table name is valid or not. By iterating over several guesses, we eventually determined that members was a valid table in the database. But is it the table used in this query? For that we need yet another test using table.field notation: it only works for tables that are actually part of this query, not merely that the table exists. SELECT email, passwd, login_id, full_name
FROM members
WHERE email = 'x' AND members.email IS NULL; --';
When this returned "Email unknown", it confirmed that our SQL was well formed and that we had properly guessed the table name. This will be important later, but we instead took a different approach in the interim.
Finding some users
At this point we have a partial idea of the structure of the members table, but we only know of one username: the random member who got our initial "Here is your password" email. Recall that we never received the message itself, only the address it was sent to. We'd like to get some more names to work with, preferably those likely to have access to more data.
The first place to start, of course, is the company's website to find who is who: the "About us" or "Contact" pages often list who's running the place. Many of these contain email addresses, but even those that don't list them can give us some clues which allow us to find them with our tool.
The idea is to submit a query that uses the LIKE clause, allowing us to do partial matches of names or email addresses in the database, each time triggering the "We sent your password" message and email. Warning: though this reveals an email address each time we run it, it also actually sends that email, which may raise suspicions. This suggests that we take it easy.
We can do the query on email name or full name (or presumably other information), each time putting in the % wildcards that LIKE supports: SELECT email, passwd, login_id, full_name
FROM members
WHERE email = 'x' OR full_name LIKE '%Bob%';
Keep in mind that even though there may be more than one "Bob", we only get to see one of them: this suggests refining our LIKE clause narrowly.
Ultimately, we may only need one valid email address to leverage our way in.
Brute-force password guessing
One can certainly attempt brute-force guessing of passwords at the main login page, but many systems make an effort to detect or even prevent this. There could be logfiles, account lockouts, or other devices that would substantially impede our efforts, but because of the non-sanitized inputs, we have another avenue that is much less likely to be so protected.
We'll instead do actual password testing in our snippet by including the email name and password directly. In our example, we'll use our victim, bob@example.com and try multiple passwords. SELECT email, passwd, login_id, full_name
FROM members
WHERE email = 'bob@example.com' AND passwd = 'hello123';
This is clearly well-formed SQL, so we don't expect to see any server errors, and we'll know we found the password when we receive the "your password has been mailed to you" message. Our mark has now been tipped off, but we do have his password.
This procedure can be automated with scripting in perl, and though we were in the process of creating this script, we ended up going down another road before actually trying it.
The database isn't readonly
So far, we have done nothing but query the database, and even though a SELECT is readonly, that doesn't mean that SQL is. SQL uses the semicolon for statement termination, and if the input is not sanitized properly, there may be nothing that prevents us from stringing our own unrelated command at the end of the query.
The most drastic example is: SELECT email, passwd, login_id, full_name
FROM members
WHERE email = 'x'; DROP TABLE members; --'; -- Boom!
The first part provides a dummy email address -- 'x' -- and we don't care what this query returns: we're just getting it out of the way so we can introduce an unrelated SQL command. This one attempts to drop (delete) the entire members table, which really doesn't seem too sporting.
This shows that not only can we run separate SQL commands, but we can also modify the database. This is promising.
Adding a new member
Given that we know the partial structure of the members table, it seems like a plausible approach to attempt adding a new record to that table: if this works, we'll simply be able to login directly with our newly-inserted credentials.
This, not surprisingly, takes a bit more SQL, and we've wrapped it over several lines for ease of presentation, but our part is still one contiguous string: SELECT email, passwd, login_id, full_name
FROM members
WHERE email = 'x';
INSERT INTO members ('email','passwd','login_id','full_name')
VALUES ('steve@unixwiz.net','hello','steve','Steve Friedl');--';
Even if we have actually gotten our field and table names right, several things could get in our way of a successful attack:
We might not have enough room in the web form to enter this much text directly (though this can be worked around via scripting, it's much less convenient).
The web application user might not have INSERT permission on the members table.
There are undoubtedly other fields in the members table, and some may require initial values, causing the INSERT to fail.
Even if we manage to insert a new record, the application itself might not behave well due to the auto-inserted NULL fields that we didn't provide values for.
A valid "member" might require not only a record in the members table, but associated information in other tables (say, "accessrights"), so adding to one table alone might not be sufficient.
In the case at hand, we hit a roadblock on either #4 or #5 - we can't really be sure -- because when going to the main login page and entering in the above username + password, a server error was returned. This suggests that fields we did not populate were vital, but nevertheless not handled properly.
A possible approach here is attempting to guess the other fields, but this promises to be a long and laborious process: though we may be able to guess other "obvious" fields, it's very hard to imagine the bigger-picture organization of this application.
We ended up going down a different road.
Mail me a password
We then realized that though we are not able to add a new record to the members database, we can modify an existing one, and this proved to be the approach that gained us entry.
From a previous step, we knew that bob@example.com had an account on the system, and we used our SQL injection to update his database record with our email address: SELECT email, passwd, login_id, full_name
FROM members
WHERE email = 'x';
UPDATE members
SET email = 'steve@unixwiz.net'
WHERE email = 'bob@example.com';
After running this, we of course received the "we didn't know your email address", but this was expected due to the dummy email address provided. The UPDATE wouldn't have registered with the application, so it executed quietly.
We then used the regular "I lost my password" link - with the updated email address - and a minute later received this email: From: system@example.com
To: steve@unixwiz.net
Subject: Intranet login
This email is in response to your request for your Intranet log in information.
Your User ID is: bob
Your password is: hello
Now it was now just a matter of following the standard login process to access the system as a high-ranked MIS staffer, and this was far superior to a perhaps-limited user that we might have created with our INSERT approach.
We found the intranet site to be quite comprehensive, and it included - among other things - a list of all the users. It's a fair bet that many Intranet sites also have accounts on the corporate Windows network, and perhaps some of them have used the same password in both places. Since it's clear that we have an easy way to retrieve any Intranet password, and since we had located an open PPTP VPN port on the corporate firewall, it should be straightforward to attempt this kind of access.
We had done a spot check on a few accounts without success, and we can't really know whether it's "bad password" or "the Intranet account name differs from the Windows account name". But we think that automated tools could make some of this easier.
Other Approaches
In this particular engagement, we obtained enough access that we did not feel the need to do much more, but other steps could have been taken. We'll touch on the ones that we can think of now, though we are quite certain that this is not comprehensive.
We are also aware that not all approaches work with all databases, and we can touch on some of them here.
Use xp_cmdshell
Microsoft's SQL Server supports a stored procedure xp_cmdshell that permits what amounts to arbitrary command execution, and if this is permitted to the web user, complete compromise of the webserver is inevitable.
What we had done so far was limited to the web application and the underlying database, but if we can run commands, the webserver itself cannot help but be compromised. Access to xp_cmdshell is usually limited to administrative accounts, but it's possible to grant it to lesser users.
Map out more database structure
Though this particular application provided such a rich post-login environment that it didn't really seem necessary to dig further, in other more limited environments this may not have been sufficient.
Being able to systematically map out the available schema, including tables and their field structure, can't help but provide more avenues for compromise of the application.
One could probably gather more hints about the structure from other aspects of the website (e.g., is there a "leave a comment" page? Are there "support forums"?). Clearly, this is highly dependent on the application and it relies very much on making good guesses.
Mitigations
We believe that web application developers often simply do not think about "surprise inputs", but security people do (including the bad guys), so there are three broad approaches that can be applied here.
Sanitize the input
It's absolutely vital to sanitize user inputs to insure that they do not contain dangerous codes, whether to the SQL server or to HTML itself. One's first idea is to strip out "bad stuff", such as quotes or semicolons or escapes, but this is a misguided attempt. Though it's easy to point out some dangerous characters, it's harder to point to all of them.
The language of the web is full of special characters and strange markup (including alternate ways of representing the same characters), and efforts to authoritatively identify all "bad stuff" are unlikely to be successful.
Instead, rather than "remove known bad data", it's better to "remove everything but known good data": this distinction is crucial. Since - in our example - an email address can contain only these characters:
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
0123456789
@.-_+
There is really no benefit in allowing characters that could not be valid, and rejecting them early - presumably with an error message - not only helps forestall SQL Injection, but also catches mere typos early rather than stores them into the database.
Sidebar on email addresses
It's important to note here that email addresses in particular are troublesome to validate programmatically, because everybody seems to have his own idea about what makes one "valid", and it's a shame to exclude a good email address because it contains a character you didn't think about.
The only real authority is RFC 2822 (which encompasses the more familiar RFC822), and it includes a fairly expansive definition of what's allowed. The truly pedantic may well wish to accept email addresses with ampersands and asterisks (among other things) as valid, but others - including this author - are satisfied with a reasonable subset that includes "most" email addresses.
Those taking a more restrictive approach ought to be fully aware of the consequences of excluding these addresses, especially considering that better techniques (prepare/execute, stored procedures) obviate the security concerns which those "odd" characters present.
Be aware that "sanitizing the input" doesn't mean merely "remove the quotes", because even "regular" characters can be troublesome. In an example where an integer ID value is being compared against the user input (say, a numeric PIN):
SELECT fieldlist
FROM table
WHERE id = 23 OR 1=1; -- Boom! Always matches!
In practice, however, this approach is highly limited because there are so few fields for which it's possible to outright exclude many of the dangerous characters. For "dates" or "email addresses" or "integers" it may have merit, but for any kind of real application, one simply cannot avoid the other mitigations.
Escape/Quotesafe the input
Even if one might be able to sanitize a phone number or email address, one cannot take this approach with a "name" field lest one wishes to exclude the likes of Bill O'Reilly from one's application: a quote is simply a valid character for this field.
One includes an actual single quote in an SQL string by putting two of them together, so this suggests the obvious - but wrong! - technique of preprocessing every string to replicate the single quotes:
SELECT fieldlist
FROM customers
WHERE name = 'Bill O''Reilly'; -- works OK
However, this naïve approach can be beaten because most databases support other string escape mechanisms. MySQL, for instance, also permits \' to escape a quote, so after input of \'; DROP TABLE users; -- is "protected" by doubling the quotes, we get:
SELECT fieldlist
FROM customers
WHERE name = '\''; DROP TABLE users; --'; -- Boom!
The expression '\'' is a complete string (containing just one single quote), and the usual SQL shenanigans follow. It doesn't stop with backslashes either: there is Unicode, other encodings, and parsing oddities all hiding in the weeds to trip up the application designer.
Getting quotes right is notoriously difficult, which is why many database interface languages provide a function that does it for you. When the same internal code is used for "string quoting" and "string parsing", it's much more likely that the process will be done properly and safely.
Some examples are the MySQL function mysql_real_escape_string() and perl DBD method $dbh->quote($value).
These methods must be used.
Use bound parameters (the PREPARE statement)
Though quotesafing is a good mechanism, we're still in the area of "considering user input as SQL", and a much better approach exists: bound parameters, which are supported by essentially all database programming interfaces. In this technique, an SQL statement string is created with placeholders - a question mark for each parameter - and it's compiled ("prepared", in SQL parlance) into an internal form.
Later, this prepared query is "executed" with a list of parameters:
Example in perl$sth = $dbh->prepare("SELECT email, userid FROM members WHERE email = ?;");
$sth->execute($email);
Thanks to Stefan Wagner, this demonstrates bound parameters in Java:
Insecure versionStatement s = connection.createStatement();
ResultSet rs = s.executeQuery("SELECT email FROM member WHERE name = "
+ formField); // *boom*
Secure versionPreparedStatement ps = connection.prepareStatement(
"SELECT email FROM member WHERE name = ?");
ps.setString(1, formField);
ResultSet rs = ps.executeQuery();
Here, $email is the data obtained from the user's form, and it is passed as positional parameter #1 (the first question mark), and at no point do the contents of this variable have anything to do with SQL statement parsing. Quotes, semicolons, backslashes, SQL comment notation - none of this has any impact, because it's "just data". There simply is nothing to subvert, so the application is be largely immune to SQL injection attacks.
There also may be some performance benefits if this prepared query is reused multiple times (it only has to be parsed once), but this is minor compared to the enormous security benefits. This is probably the single most important step one can take to secure a web application.
Limit database permissions and segregate users
In the case at hand, we observed just two interactions that are made not in the context of a logged-in user: "log in" and "send me password". The web application ought to use a database connection with the most limited rights possible: query-only access to the members table, and no access to any other table.
The effect here is that even a "successful" SQL injection attack is going to have much more limited success. Here, we'd not have been able to do the UPDATE request that ultimately granted us access, so we'd have had to resort to other avenues.
Once the web application determined that a set of valid credentials had been passed via the login form, it would then switch that session to a database connection with more rights.
It should go almost without saying that sa rights should never be used for any web-based application.
Use stored procedures for database access
When the database server supports them, use stored procedures for performing access on the application's behalf, which can eliminate SQL entirely (assuming the stored procedures themselves are written properly).
By encapsulating the rules for a certain action - query, update, delete, etc. - into a single procedure, it can be tested and documented on a standalone basis and business rules enforced (for instance, the "add new order" procedure might reject that order if the customer were over his credit limit).
For simple queries this might be only a minor benefit, but as the operations become more complicated (or are used in more than one place), having a single definition for the operation means it's going to be more robust and easier to maintain.
Note: it's always possible to write a stored procedure that itself constructs a query dynamically: this provides no protection against SQL Injection - it's only proper binding with prepare/execute or direct SQL statements with bound variables that provide this protection.
Isolate the webserver
Even having taken all these mitigation steps, it's nevertheless still possible to miss something and leave the server open to compromise. One ought to design the network infrastructure to assume that the bad guy will have full administrator access to the machine, and then attempt to limit how that can be leveraged to compromise other things.
For instance, putting the machine in a DMZ with extremely limited pinholes "inside" the network means that even getting complete control of the webserver doesn't automatically grant full access to everything else. This won't stop everything, of course, but it makes it a lot harder.
Configure error reporting
The default error reporting for some frameworks includes developer debugging information, and this cannot be shown to outside users. Imagine how much easier a time it makes for an attacker if the full query is shown, pointing to the syntax error involved.
This information is useful to developers, but it should be restricted - if possible - to just internal users.
Note that not all databases are configured the same way, and not all even support the same dialect of SQL (the "S" stands for "Structured", not "Standard"). For instance, most versions of MySQL do not support subselects, nor do they usually allow multiple statements: these are substantially complicating factors when attempting to penetrate a network.
HISTORY OF OPERATING SYSTEM
Earliest Computers
The first computers were made with intricate gear systems by the Greeks. These computers turned out to be too delicate for the technological capabilities of the time and were abandoned as impractical. The Antikythera mechanism, discovered in a shipwreck in 1900, is an early mechanical analog computer from between 150 BCE and 100 BCE. The Antikythera mechanism used a system of 37 gears to compute the positions of the sun and the moon through the zodiac on the Egyptian calendar, and possibly also the fixed stars and five planets known in antiquity (Mercury, Venus, Mars, Jupiter, and Saturn) for any time in the future or past. The system of gears added and subtracted angular velocities to compute differentials. The Antikythera mechanism could accurately predict eclipses and could draw up accurate astrological charts for important leaders. It is likely that the Antikythera mechanism was based on an astrological computer created by Archimedes of Syracuse in the 3rd century BCE.
The first modern computers were made by the Inca using ropes and pulleys. Knots in the ropes served the purpose of binary digits. The Inca had several of these computers and used them for tax and government records. In addition to keeping track of taxes, the Inca computers held data bases on all of the resources of the Inca empire, allowing for efficient allocation of resources in response to local disasters (storms, drought, earthquakes, etc.). Spanish soldiers acting on orders of Roman Catholic priests destroyed all but one of the Inca computers in the mistaken belief that any device that could give accurate information about distant conditions must be a divination device powered by the Christian “Devil” (and many modern Luddites continue to view computers as Satanically possessed devices).
In the 1800s, the first computers were programmable devices for controlling the weaving machines in the factories of the Industrial Revolution. Created by Charles Babbage, these early computers used Punch cards as data storage (the cards contained the control codes for the various patterns). These cards were very similiar to the famous Hollerinth cards developed later. The first computer programmer was Lady Ada, for whom the Ada programming language is named.
In 1833 Charles babbage proposed a mechanical computer with all of the elements of a modern computer, including control, arithmetic, and memory, but the technology of the day couldn’t produce gears with enough precision or reliability to make his computer possible.
In the 1900s, researchers started experimenting with both analog and digital computers using vacuum tubes. Some of the most successful early computers were analog computers, capable of performing advanced calculus problems rather quickly. But the real future of computing was digital rather than analog. Building on the technology and math used for telephone and telegraph switching networks, researchers started building the first electronic digital computers.
The first modern computer was the German Zuse computer (Z3) in 1941. In 1944 Howard Aiken of Harvard University created the Harvard Mark I and Mark II. The Mark I was primarily mechanical, while the Mark II was primarily based on reed relays. Telephone and telegraph companies had been using reed relays for the logic circuits needed for large scale switching networks.
The first modern electronic computer was the ENIAC in 1946, using 18,000 vacuum tubes. See below for information on Von Neumann’s important contributions.
The first solid-state (or transistor) computer was the TRADIC, built at Bell Laboratories in 1954. The transistor had previously been invented at Bell Labs in 1948.
VON Neumann architecture
John Louis von Neumann, mathematician (born János von Neumann 28 December 1903 in Budapest, Hungary, died 8 February 1957 in Washington, D.C.), proposed the stored program concept while professor of mathemtics (one of the orginal six) at Princeton University’s Institute for Advanced Services, in which programs (code) are stored in the same memory as data. The computer knows the difference between code and data by which it is attempting to access at any given moment. When evaluating code, the binary numbers are decoded by some kind of physical logic circuits (later other methods, such as microprogramming, were introduced), and then the instructions are run in hardware. This design is called von Neumann architecture and has been used in almost every digital computer ever made.
Von Neumann architecture introduced flexibility to computers. Previous computers had their programming hard wired into the computer. A particular computer could only do one task (at the time, mostly building artillery tables) and had to be physically rewired to do any new task.
By using numeric codes, von Neumann computers could be reprogrammed for a wide variety of problems, with the decode logic remaining the same.
As processors (especially super computers) get ever faster, the von Neumann bottleneck is starting to become an issue. With data and code both being accessed over the same circuit lines, the processor has to wait for one while the other is being fetched (or written). Well designed data and code caches help, but only when the requested access is already loaded into cache. Some researchers are now experimenting with Harvard architecture to solve the von Neumann bottleneck. In Harvard arrchitecture, named for Howard Aiken’s experimental Harvard Mark I (ASCC) calculator [computer] at Harvard University, a second set of data and address lines along with a second set of memory are set aside for executable code, removing part of the conflict with memory accesses for data.
Von Neumann became an American citizen in 1933 to be eligible to help on top secret work during World War II. There is a story that Oskar Morganstern coached von Neumann and Kurt Gödel on the U.S. Constitution and American history while driving them to their immigration interview. Morganstern asked if they had any questions, and Gödel replied that he had no questions, but had found some logical inconsistencies in the Constitution that he wanted to ask the Immigration officers about. Morganstern recommended that he not ask questions, but just answer them.
Von Neumann occassionally worked with Alan Turing in 1936 through 1938 when Turing was a graduate student at Princeton. Von Neumann was exposed to the concepts of logical design and universal machine proposed in Turing’s 1934 paper “On Computable Numbers with an Application to the Entschiedungs-problem”.
Von Neumann worked with such early computers as the Harvard Mark I, ENIAC, EDVAC, and his own IAS computer.
Early research into computers involved doing the computations to create tables, especially artillery firing tables. Von Neumann was convinced that the future of computers involved applied mathematics to solve specific problems rather than mere table generation. Von Neumann was the first person to use computers for mathematical physics and economics, proving the utility of a general purpose computer.
Von Neumann proposed the concept of stored programs in the 1945 paper “First Draft of a Report on the EDVAC”. Influenced by the idea, Maurice Wilkes of the Cambridge University Mathematical Laboratory designed and built the EDSAC, the world’s first operational, production, stored-program computer.
The first stored computer program ran on the Manchester Mark I [computer] on June 21, 1948.
Von Neumann foresaw the advantages of parallelism in computers, but because of construction limitations of the time, he worked on sequential systems.
Von Neumann advocated the adoption of the bit as the measurement of computer memory and solved many of the problems regarding obtaining reliable answers from unreliable computer components.
Interestingly, von Neumann was opposed to the idea of compilers. When shown the idea for FORTRAN in 1954, von Neumann asked “Why would you want more than machine language?”. Von Neumann had graduate students hand assemble programs into binary code for the IAS machine. Donald Gillies, a student at Princeton, created an assembler to do the work. Von Neumann was angry, claiming “It is a waste of a valuable scientific computing instrument to use it to do clerical work”.
Von Neumann also did important work in set theory (including measure theory), the mathematical foundation for quantum theory (including statistical mechanics), self-adjoint algebras of bounded linear operators on a Hilbert space closed in weak operator topology, non-linear partial differential equations, and automata theory (later applied to cmputers). His work in economics included his 1937 paper “A Model of General Economic Equilibrium” on a multi-sectoral growth model and his 1944 book “Theory of Games and Economic Behavior” (co-authored with Morgenstern) on game theory and uncertainty.
I leave the discussion of von Neumann with a couple of quotations:
“If people do not believe that mathematics is simple, it is only because they do not realize how complicated life is.”
“Anyone who considers arithmetical methods of producing random numbers is, of course, in a state of sin.”
bare hardware
In the earliest days of electronic digital computing, everything was done on the bare hardware. Very few computers existed and those that did exist were experimental in nature. The researchers who were making the first computers were also the programmers and the users. They worked directly on the “bare hardware”. There was no operating system. The experimenters wrote their programs in assembly language and a running program had complete control of the entire computer. Debugging consisted of a combination of fixing both the software and hardware, rewriting the object code and changing the actual computer itself.
The lack of any operating system meant that only one person could use a computer at a time. Even in the research lab, there were many researchers competing for limited computing time. The first solution was a reservation system, with researchers signing up for specific time slots.
The high cost of early computers meant that it was essential that the rare computers be used as efficiently as possible. The reservation system was not particularly efficient. If a researcher finished work early, the computer sat idle until the next time slot. If the researcher's time ran out, the researcher might have to pack up his or her work in an incomplete state at an awkward moment to make room for the next researcher. Even when things were going well, a lot of the time the computer actually sat idle while the researcher studied the results (or studied memory of a crashed program to figure out what went wrong).
computer operators
The solution to this problem was to have programmers prepare their work off-line on some input medium (often on punched cards, paper tape, or magnetic tape) and then hand the work to a computer operator. The computer operator would load up jobs in the order received (with priority overrides based on politics and other factors). Each job still ran one at a time with complete control of the computer, but as soon as a job finished, the operator would transfer the results to some output medium (punched tape, paper tape, magnetic tape, or printed paper) and deliver the results to the appropriate programmer. If the program ran to completion, the result would be some end data. If the program crashed, memory would be transferred to some output medium for the programmer to study (because some of the early business computing systems used magnetic core memory, these became known as “core dumps”)
device drivers and library functions
Soon after the first successes with digital computer experiments, computers moved out of the lab and into practical use. The first practical application of these experimental digital computers was the generation of artillery tables for the British and American armies. Much of the early research in computers was paid for by the British and American militaries. Business and scientific applications followed.
As computer use increased, programmers noticed that they were duplicating the same efforts.
Every programmer was writing his or her own routines for I/O, such as reading input from a magnetic tape or writing output to a line printer. It made sense to write a common device driver for each input or putput device and then have every programmer share the same device drivers rather than each programmer writing his or her own. Some programmers resisted the use of common device drivers in the belief that they could write “more efficient” or faster or "“better” device drivers of their own.
Additionally each programmer was writing his or her own routines for fairly common and repeated functionality, such as mathematics or string functions. Again, it made sense to share the work instead of everyone repeatedly “reinventing the wheel”. These shared functions would be organized into libraries and could be inserted into programs as needed. In the spirit of cooperation among early researchers, these library functions were published and distributed for free, an early example of the power of the open source approach to software development.
1950s
Some operating systems from the 1950s include: FORTRAN Monitor System, General Motors Operating System, Input Output System, SAGE, and SOS.
SAGE (Semi-Automatic Ground Environment), designed to monitor weapons systems, was the first real time control system.
batch systems
Batch systems automated the early approach of having human operators load one program at a time. Instead of having a human operator load each program, software handled the scheduling of jobs. In addition to programmers submitting their jobs,, end users could submit requests to run specific programs with specific data sets (usually stored in files or on cards). The operating system would schedule “batches” of related jobs. Output (punched cards, magnetic tapes, printed material, etc.) would be returned to each user.
Examples of operating systems that were primarily batch-oriented include: BKY, BOS/360, BPS/360, CAL, and Chios.
early 1960s
Some operating systems from the early 1960s include: Admiral, B1, B2, B3, B4, Basic Executive System, BOS/360, EXEC I, EXEC II, Honeywell Executive System, IBM 1410/1710 OS, IBSYS, Input Output Control System, Master Control Program, and SABRE.
The first major transaction processing system was SABRE (Semi-Automatic Business Related Environment), developed by IBM and American Airlines.w78
system calls
The first operating system to introduce system calls was University of Machester’s Atlas I Supervisor.w78
mid 1960s
Some operating systems from the mid-1960s include: Atlas I Supervisor, DOS/360, Input Output Selector, and Master Control Program.
late 1960s
Some operating systems from the late-1960s include: BPS/360, CAL, CHIPPEWA, EXEC 3, and EXEC 4, EXEC 8, GECOS III, George 1, George 2, George 3, George 4, IDASYS, MASTER, Master Control Program, OS/MFT, OS/MFT-II, OS/MVT, OS/PCP, and RCA DOS.
microprocessors
In 1968 a group of scientists and engineers from Mitre Corporation (Bedford, Massachusetts) created Viatron Computer company and an intelligent data terminal using an 8-bit LSI microprocessor from PMOS technology. A year later in 1969 Viatron created the 2140, the first 4-bit LSI microprocessor. At the time MOS was used only for a small number of calculators and there simply wasn’t enough worldwide manufacturing capacity to build these computers in quantity.
Other companies saw the benefit of MOS, starting with Intel’s 1971 release of the 4-bit 4004 as the first commercially available microprocessor. In 1972 Rockwell released the PPS-4 microprocessor, Fairchild released the PPS-25 microprocessor, and Intel released the 8-bit 8008 microprocessor. In 1973 National released the IMP microprocessor.
In 1973 Intel released the faster NMOS 8080 8-bit microprocessor, the first in a long series of microprocessors that led to the current Pentium.
In 1974 Motorola released the 6800, which included two accumulators, index registers, and memory-mapped I/O. Monolithic Memories introduced bit-slice microprocessing. In 1975 Texas Instruments introduced a 4-bit slice microprocessor and Fairchild introduced the F-8 microprocessor.
early 1970s
Some operating systems from the early-1970s include: BKY, Chios, DOS/VS, Master Control Program, OS/VS1, and UNIX.
In 1970 Ken Thompson of AT&T Bell Labs suggested the name “Unix” for the operating system that had been under development since 1969. The name was an intentional pun on AT&T’s earlier Multics project (uni- means “one”, multi- means “many”).
mid 1970s
Some operating systems from the mid-1970s include: Master Control Program.
In 1973 the kernel of Unix was rewritten in the C programming language. This made Unix the world’s first portable operating system, capable of being easily ported (moved) to any hardware. This was a major advantage for Unix and led to its widespread use in the multi-platform environments of colleges and universities.
late 1970s
Some operating systems from the late-1970s include: EMAS 2900, General Comprehensive OS, OpenVMS, OS/MVS.
1980s
Some operating systems from the 1980s include: AmigaOS, DOS/VSE, HP-UX, Macintosh, MS-DOS, and ULTRIX.
1990s
Some operating systems from the 1990s include: BeOS, BSDi, FreeBSD, NeXT, OS/2, Windows 95, Windows 98, and Windows NT.
2000s
Some operating systems from the 2000s include: Mac OS X, Syllable, Windows 2000, Windows Server 2003, Windows ME, and Windows XP.
The first computers were made with intricate gear systems by the Greeks. These computers turned out to be too delicate for the technological capabilities of the time and were abandoned as impractical. The Antikythera mechanism, discovered in a shipwreck in 1900, is an early mechanical analog computer from between 150 BCE and 100 BCE. The Antikythera mechanism used a system of 37 gears to compute the positions of the sun and the moon through the zodiac on the Egyptian calendar, and possibly also the fixed stars and five planets known in antiquity (Mercury, Venus, Mars, Jupiter, and Saturn) for any time in the future or past. The system of gears added and subtracted angular velocities to compute differentials. The Antikythera mechanism could accurately predict eclipses and could draw up accurate astrological charts for important leaders. It is likely that the Antikythera mechanism was based on an astrological computer created by Archimedes of Syracuse in the 3rd century BCE.
The first modern computers were made by the Inca using ropes and pulleys. Knots in the ropes served the purpose of binary digits. The Inca had several of these computers and used them for tax and government records. In addition to keeping track of taxes, the Inca computers held data bases on all of the resources of the Inca empire, allowing for efficient allocation of resources in response to local disasters (storms, drought, earthquakes, etc.). Spanish soldiers acting on orders of Roman Catholic priests destroyed all but one of the Inca computers in the mistaken belief that any device that could give accurate information about distant conditions must be a divination device powered by the Christian “Devil” (and many modern Luddites continue to view computers as Satanically possessed devices).
In the 1800s, the first computers were programmable devices for controlling the weaving machines in the factories of the Industrial Revolution. Created by Charles Babbage, these early computers used Punch cards as data storage (the cards contained the control codes for the various patterns). These cards were very similiar to the famous Hollerinth cards developed later. The first computer programmer was Lady Ada, for whom the Ada programming language is named.
In 1833 Charles babbage proposed a mechanical computer with all of the elements of a modern computer, including control, arithmetic, and memory, but the technology of the day couldn’t produce gears with enough precision or reliability to make his computer possible.
In the 1900s, researchers started experimenting with both analog and digital computers using vacuum tubes. Some of the most successful early computers were analog computers, capable of performing advanced calculus problems rather quickly. But the real future of computing was digital rather than analog. Building on the technology and math used for telephone and telegraph switching networks, researchers started building the first electronic digital computers.
The first modern computer was the German Zuse computer (Z3) in 1941. In 1944 Howard Aiken of Harvard University created the Harvard Mark I and Mark II. The Mark I was primarily mechanical, while the Mark II was primarily based on reed relays. Telephone and telegraph companies had been using reed relays for the logic circuits needed for large scale switching networks.
The first modern electronic computer was the ENIAC in 1946, using 18,000 vacuum tubes. See below for information on Von Neumann’s important contributions.
The first solid-state (or transistor) computer was the TRADIC, built at Bell Laboratories in 1954. The transistor had previously been invented at Bell Labs in 1948.
VON Neumann architecture
John Louis von Neumann, mathematician (born János von Neumann 28 December 1903 in Budapest, Hungary, died 8 February 1957 in Washington, D.C.), proposed the stored program concept while professor of mathemtics (one of the orginal six) at Princeton University’s Institute for Advanced Services, in which programs (code) are stored in the same memory as data. The computer knows the difference between code and data by which it is attempting to access at any given moment. When evaluating code, the binary numbers are decoded by some kind of physical logic circuits (later other methods, such as microprogramming, were introduced), and then the instructions are run in hardware. This design is called von Neumann architecture and has been used in almost every digital computer ever made.
Von Neumann architecture introduced flexibility to computers. Previous computers had their programming hard wired into the computer. A particular computer could only do one task (at the time, mostly building artillery tables) and had to be physically rewired to do any new task.
By using numeric codes, von Neumann computers could be reprogrammed for a wide variety of problems, with the decode logic remaining the same.
As processors (especially super computers) get ever faster, the von Neumann bottleneck is starting to become an issue. With data and code both being accessed over the same circuit lines, the processor has to wait for one while the other is being fetched (or written). Well designed data and code caches help, but only when the requested access is already loaded into cache. Some researchers are now experimenting with Harvard architecture to solve the von Neumann bottleneck. In Harvard arrchitecture, named for Howard Aiken’s experimental Harvard Mark I (ASCC) calculator [computer] at Harvard University, a second set of data and address lines along with a second set of memory are set aside for executable code, removing part of the conflict with memory accesses for data.
Von Neumann became an American citizen in 1933 to be eligible to help on top secret work during World War II. There is a story that Oskar Morganstern coached von Neumann and Kurt Gödel on the U.S. Constitution and American history while driving them to their immigration interview. Morganstern asked if they had any questions, and Gödel replied that he had no questions, but had found some logical inconsistencies in the Constitution that he wanted to ask the Immigration officers about. Morganstern recommended that he not ask questions, but just answer them.
Von Neumann occassionally worked with Alan Turing in 1936 through 1938 when Turing was a graduate student at Princeton. Von Neumann was exposed to the concepts of logical design and universal machine proposed in Turing’s 1934 paper “On Computable Numbers with an Application to the Entschiedungs-problem”.
Von Neumann worked with such early computers as the Harvard Mark I, ENIAC, EDVAC, and his own IAS computer.
Early research into computers involved doing the computations to create tables, especially artillery firing tables. Von Neumann was convinced that the future of computers involved applied mathematics to solve specific problems rather than mere table generation. Von Neumann was the first person to use computers for mathematical physics and economics, proving the utility of a general purpose computer.
Von Neumann proposed the concept of stored programs in the 1945 paper “First Draft of a Report on the EDVAC”. Influenced by the idea, Maurice Wilkes of the Cambridge University Mathematical Laboratory designed and built the EDSAC, the world’s first operational, production, stored-program computer.
The first stored computer program ran on the Manchester Mark I [computer] on June 21, 1948.
Von Neumann foresaw the advantages of parallelism in computers, but because of construction limitations of the time, he worked on sequential systems.
Von Neumann advocated the adoption of the bit as the measurement of computer memory and solved many of the problems regarding obtaining reliable answers from unreliable computer components.
Interestingly, von Neumann was opposed to the idea of compilers. When shown the idea for FORTRAN in 1954, von Neumann asked “Why would you want more than machine language?”. Von Neumann had graduate students hand assemble programs into binary code for the IAS machine. Donald Gillies, a student at Princeton, created an assembler to do the work. Von Neumann was angry, claiming “It is a waste of a valuable scientific computing instrument to use it to do clerical work”.
Von Neumann also did important work in set theory (including measure theory), the mathematical foundation for quantum theory (including statistical mechanics), self-adjoint algebras of bounded linear operators on a Hilbert space closed in weak operator topology, non-linear partial differential equations, and automata theory (later applied to cmputers). His work in economics included his 1937 paper “A Model of General Economic Equilibrium” on a multi-sectoral growth model and his 1944 book “Theory of Games and Economic Behavior” (co-authored with Morgenstern) on game theory and uncertainty.
I leave the discussion of von Neumann with a couple of quotations:
“If people do not believe that mathematics is simple, it is only because they do not realize how complicated life is.”
“Anyone who considers arithmetical methods of producing random numbers is, of course, in a state of sin.”
bare hardware
In the earliest days of electronic digital computing, everything was done on the bare hardware. Very few computers existed and those that did exist were experimental in nature. The researchers who were making the first computers were also the programmers and the users. They worked directly on the “bare hardware”. There was no operating system. The experimenters wrote their programs in assembly language and a running program had complete control of the entire computer. Debugging consisted of a combination of fixing both the software and hardware, rewriting the object code and changing the actual computer itself.
The lack of any operating system meant that only one person could use a computer at a time. Even in the research lab, there were many researchers competing for limited computing time. The first solution was a reservation system, with researchers signing up for specific time slots.
The high cost of early computers meant that it was essential that the rare computers be used as efficiently as possible. The reservation system was not particularly efficient. If a researcher finished work early, the computer sat idle until the next time slot. If the researcher's time ran out, the researcher might have to pack up his or her work in an incomplete state at an awkward moment to make room for the next researcher. Even when things were going well, a lot of the time the computer actually sat idle while the researcher studied the results (or studied memory of a crashed program to figure out what went wrong).
computer operators
The solution to this problem was to have programmers prepare their work off-line on some input medium (often on punched cards, paper tape, or magnetic tape) and then hand the work to a computer operator. The computer operator would load up jobs in the order received (with priority overrides based on politics and other factors). Each job still ran one at a time with complete control of the computer, but as soon as a job finished, the operator would transfer the results to some output medium (punched tape, paper tape, magnetic tape, or printed paper) and deliver the results to the appropriate programmer. If the program ran to completion, the result would be some end data. If the program crashed, memory would be transferred to some output medium for the programmer to study (because some of the early business computing systems used magnetic core memory, these became known as “core dumps”)
device drivers and library functions
Soon after the first successes with digital computer experiments, computers moved out of the lab and into practical use. The first practical application of these experimental digital computers was the generation of artillery tables for the British and American armies. Much of the early research in computers was paid for by the British and American militaries. Business and scientific applications followed.
As computer use increased, programmers noticed that they were duplicating the same efforts.
Every programmer was writing his or her own routines for I/O, such as reading input from a magnetic tape or writing output to a line printer. It made sense to write a common device driver for each input or putput device and then have every programmer share the same device drivers rather than each programmer writing his or her own. Some programmers resisted the use of common device drivers in the belief that they could write “more efficient” or faster or "“better” device drivers of their own.
Additionally each programmer was writing his or her own routines for fairly common and repeated functionality, such as mathematics or string functions. Again, it made sense to share the work instead of everyone repeatedly “reinventing the wheel”. These shared functions would be organized into libraries and could be inserted into programs as needed. In the spirit of cooperation among early researchers, these library functions were published and distributed for free, an early example of the power of the open source approach to software development.
1950s
Some operating systems from the 1950s include: FORTRAN Monitor System, General Motors Operating System, Input Output System, SAGE, and SOS.
SAGE (Semi-Automatic Ground Environment), designed to monitor weapons systems, was the first real time control system.
batch systems
Batch systems automated the early approach of having human operators load one program at a time. Instead of having a human operator load each program, software handled the scheduling of jobs. In addition to programmers submitting their jobs,, end users could submit requests to run specific programs with specific data sets (usually stored in files or on cards). The operating system would schedule “batches” of related jobs. Output (punched cards, magnetic tapes, printed material, etc.) would be returned to each user.
Examples of operating systems that were primarily batch-oriented include: BKY, BOS/360, BPS/360, CAL, and Chios.
early 1960s
Some operating systems from the early 1960s include: Admiral, B1, B2, B3, B4, Basic Executive System, BOS/360, EXEC I, EXEC II, Honeywell Executive System, IBM 1410/1710 OS, IBSYS, Input Output Control System, Master Control Program, and SABRE.
The first major transaction processing system was SABRE (Semi-Automatic Business Related Environment), developed by IBM and American Airlines.w78
system calls
The first operating system to introduce system calls was University of Machester’s Atlas I Supervisor.w78
mid 1960s
Some operating systems from the mid-1960s include: Atlas I Supervisor, DOS/360, Input Output Selector, and Master Control Program.
late 1960s
Some operating systems from the late-1960s include: BPS/360, CAL, CHIPPEWA, EXEC 3, and EXEC 4, EXEC 8, GECOS III, George 1, George 2, George 3, George 4, IDASYS, MASTER, Master Control Program, OS/MFT, OS/MFT-II, OS/MVT, OS/PCP, and RCA DOS.
microprocessors
In 1968 a group of scientists and engineers from Mitre Corporation (Bedford, Massachusetts) created Viatron Computer company and an intelligent data terminal using an 8-bit LSI microprocessor from PMOS technology. A year later in 1969 Viatron created the 2140, the first 4-bit LSI microprocessor. At the time MOS was used only for a small number of calculators and there simply wasn’t enough worldwide manufacturing capacity to build these computers in quantity.
Other companies saw the benefit of MOS, starting with Intel’s 1971 release of the 4-bit 4004 as the first commercially available microprocessor. In 1972 Rockwell released the PPS-4 microprocessor, Fairchild released the PPS-25 microprocessor, and Intel released the 8-bit 8008 microprocessor. In 1973 National released the IMP microprocessor.
In 1973 Intel released the faster NMOS 8080 8-bit microprocessor, the first in a long series of microprocessors that led to the current Pentium.
In 1974 Motorola released the 6800, which included two accumulators, index registers, and memory-mapped I/O. Monolithic Memories introduced bit-slice microprocessing. In 1975 Texas Instruments introduced a 4-bit slice microprocessor and Fairchild introduced the F-8 microprocessor.
early 1970s
Some operating systems from the early-1970s include: BKY, Chios, DOS/VS, Master Control Program, OS/VS1, and UNIX.
In 1970 Ken Thompson of AT&T Bell Labs suggested the name “Unix” for the operating system that had been under development since 1969. The name was an intentional pun on AT&T’s earlier Multics project (uni- means “one”, multi- means “many”).
mid 1970s
Some operating systems from the mid-1970s include: Master Control Program.
In 1973 the kernel of Unix was rewritten in the C programming language. This made Unix the world’s first portable operating system, capable of being easily ported (moved) to any hardware. This was a major advantage for Unix and led to its widespread use in the multi-platform environments of colleges and universities.
late 1970s
Some operating systems from the late-1970s include: EMAS 2900, General Comprehensive OS, OpenVMS, OS/MVS.
1980s
Some operating systems from the 1980s include: AmigaOS, DOS/VSE, HP-UX, Macintosh, MS-DOS, and ULTRIX.
1990s
Some operating systems from the 1990s include: BeOS, BSDi, FreeBSD, NeXT, OS/2, Windows 95, Windows 98, and Windows NT.
2000s
Some operating systems from the 2000s include: Mac OS X, Syllable, Windows 2000, Windows Server 2003, Windows ME, and Windows XP.
Wednesday, August 26, 2009
Windows XP Mode for Windows 7 (Part 2)
Introduction
In the first part of this article series, I explained why I believe that the Windows XP feature that will be available for some editions of Windows 7 is going to change the future of the entire Windows franchise. In this article, I want to take a step back and show you what Windows XP Mode really looks like. I am also excited to show you some long overdue improvements in virtual machine technology.
Windows XP Mode
In my first article, I explained that in its simplest form, Windows XP Mode was nothing more than a fully licensed copy of Windows XP running within the latest version of Microsoft’s Virtual PC. I never really showed you what it was like to use Windows XP Mode though, so I wanted to give you a little tour. If you look at Figure A, you can see the Windows XP virtual machine running on top of the Windows 7 desktop. In case you are wondering, what you see in the figure is a default configuration. I placed two icons onto the Windows 7 desktop for my screen capture program, but everything else that you see is what Windows XP Mode will look like after a fresh installation.

Figure A: This is what the Windows XP virtual machine looks like
Application Compatibility
As I explained in the first part of this article series, the most significant aspect of Windows XP mode is that it allows you to run applications that were designed for Windows XP, either through the Windows XP GUI, or through the Windows 7 GUI. To show you how this works, take a look at Figure B. As you can see in the figure, I have installed a legacy application called PentaZip into the Windows XP virtual machine. An icon for this application appears on the Windows XP desktop.

Figure B: I have installed an older application into the Windows XP virtual machine
So far this is no different than what we can already do by using Windows Vista and Virtual PC 2007. If you look at Figure C though, you will notice that PentaZip is available on the Windows 7 Start menu at Start | Windows Virtual PC | Virtual Windows XP Applications. The operating system created the Start menu link to the application all by itself. I did not have to do anything other than to install the application within the Windows XP virtual machine.

Figure C: My Windows XP applications are accessible through the Windows 7 Start menu
One thing that you need to know about running the Windows XP applications through the Windows 7 GUI is that you can only do so if you have logged out of the Windows XP GUI, and closed the virtual machine. If you fail to log off, you will receive a message similar to the one that’s shown in Figure D. As you can see in the figure, you have a choice of either opening the virtual machine or running the virtualized application.

Figure D: The Windows XP virtual machine must be closed before you can run virtualized applications through the Windows 7 GUI
If you look at Figure E, you can see that I have closed my Windows XP virtual machine, and that I am running my virtualized application through Windows 7. Virtualized applications take a bit longer to load than applications that are installed natively through Windows 7 do, but aside from that, there is not much of a difference between running a native application and running a virtual application. In fact, you would be hard pressed to tell that the application shown in Figure E was a virtual application.

Figure E: This is what it looks like when you run a virtual application in Windows 7
Note:
I know that some of you are probably wondering about system resource consumption. By default, the Windows XP virtual machine consumes 256 MB of RAM, but the RAM and other system resources that are used by the virtual machine are adjustable.
Improvements in Virtual PC
As I stated earlier, Windows XP Mode consists of a copy of Windows XP running inside of Microsoft’s latest version of Virtual PC. As with previous versions of Virtual PC, you are not just limited to running Windows XP. That being the case, I think that it makes sense to wrap things up by showing you some of the improvements that Microsoft has made in this latest version of Virtual PC.
If you took more than a casual glance at Figure A, you probably noticed two of the improvements right off the bat. First, the latest version of Virtual PC features a Control Alt Delete icon that you can use to issue a Ctrl + Alt + Delete request to the guest operating system without having to go through any menus. Obviously, this is not an earth shattering change, but it is handy nonetheless, so I wanted to at least mention it.
A much more significant improvement is that Virtual PC now supports USB device access for guest operating systems! I for one, have always found it extremely frustrating that I have not been able to access USB devices from within my virtual machines. This limitation does not just apply to Virtual PC, but it exists in Microsoft’s Virtual Server and Hyper-V as well.
If you look at Figure F, you can see that you can gain access to a USB device simply by selecting the device from Virtual PC’s USB menu. Of course the virtual machine does require a driver for the USB device.

Figure F: Virtual PC now supports USB devices
I should mention that Windows 7 requires that an operating system have exclusive control over a USB device. If you choose to use a USB device within a guest operating system, the host operating system will not have access to the device until you release it. Figure G shows an example of a warning message to this effect.

Figure G: USB devices are used exclusively by a single operating system
One last improvement that I want to show you is shown in Figure H. As you can see in the Figure, the My Computer window lists my USB hard drive within the virtual machine (Drive E:). However, you will also notice several drive mappings in the Other section. These drive mappings map to the host machine’s physical drives and to any network drives that are mapped to the host operating system. Again, Windows performs these mappings automatically. This means that you finally have the ability to access your local hard drives from within a virtual machine!

Figure H: The guest OS automatically maps to the host operating system’s drives
Conclusion
As you can see, Windows XP mode and the new version of Virtual PC offer tremendous potential. I honestly do believe that the technology being used in Windows XP Mode will reshape the future of the entire Windows franchise for many versions to come.
Windows XP Mode for Windows 7 (Part 1)
Introduction
Most people think of Windows 7’s Windows XP Mode solely as a backward compatibility mechanism. In this article I will explain why this feature has the potential to change the way that Microsoft designs all future Windows operating systems.
By now I have no doubt that you are all aware of the hype surrounding Windows XP Mode for Windows 7. What you might not realize though is that Windows XP Mode is much, much more than just a backward compatibility solution. This technology has major implications that dramatically alter all future versions of the Windows franchise. In this article, I will tell you why I believe this to be the case.
Why Windows XP Mode Got a Bad Name
When it was first announced (or leaked) that Windows 7 was going to contain Windows XP mode for backward compatibility, most of the posts on the Internet made it sound as though Windows 7 was going to ship with a fully licensed copy of Windows XP running inside of a virtual machine.
I have to tell you that I was less than impressed with such posts. After all, you can use Virtual PC 2007 to run Windows XP inside a virtual machine with Vista. Even if Microsoft threw in a Windows XP license, most of the people who this sort of feature would appeal to already have Windows XP licenses. As such, I wrongfully assumed that the Windows XP Mode feature was a marketing gimmick designed to convince the public that Windows 7 was not going to be plagued by the same types of compatibility problems that Vista has come to be known for.
Setting the Myths Straight
The myths that I cited in the section above are full of half truths. I want to start out by setting the record straight, and then I will go on to explain why Windows XP Mode is so important.
You have probably heard that Windows XP Mode is going to be based on Virtual PC technology. That part is true. Unfortunately, Virtual PC has gotten a bad rap for being slow and inefficient because early versions of virtual PC had to pass all of the guest machine’s hardware calls through the host operating system. However, Virtual PC 2007 has always supported hardware assisted virtualization, as shown in Figure A.

Figure A: Virtual PC 2007 supports hardware assisted virtualization
Virtual PC 2007’s hardware assisted virtualization is not a Hyper-V based hypervisor, but guest machines do run a whole lot faster when you enable hardware based virtualization. Keep in mind though, that Windows 7 is going to use Virtual PC code that has been updated. This code is not based on Hyper-V either, but I would not be a bit surprised to see Hyper-V become the standard in Windows 8.
The next myth that I want to set straight is that Windows 7 will offer Windows XP mode right out of the box. If you want to enable Windows XP mode, then you are going to have to download an add-on. This add-on, which is going to be considered an out of band update, will be freely available to anyone who has Windows 7 Professional, Enterprise, or Ultimate edition. If you would like to try Windows XP Mode today, you can download the current beta version here.
OK, now for the really important part… When you need to run an application in Windows XP mode, those applications are not going to be limited to running inside a virtual machine. Well, actually they will be running in a virtual machine, but you would not have to be confined to using the virtual machine’s GUI to run your applications. You can install an application in a Windows environment, but run that application through the Windows 7 interface alongside your other applications.
Why is This Such a Big Deal?
Obviously it is convenient to be able to run your legacy applications alongside your newer applications, but in the end you may be wondering why I said that I think that Windows XP mode will have major implications that could alter the future of the entire Windows franchise.
In order to understand why I say this, you need to have a bit of historical prospective. Windows 95 was Microsoft’s first major 32-bit version of Windows (actually Windows for workgroups 3.11 was the first, but I don’t consider that to be a major release). At any rate, Windows 95 was designed to natively run 32-bit applications, but at the time there were still a lot of people running 16-bit applications that were designed to run on Windows 3.1. In order to facilitate the use of these legacy applications, Microsoft developed a 16-bit mutex for Windows 95. The way that the architecture was implemented kept 16-bit code separate from 32-bit code, and there was even a separate multitasking engine for 16-bit applications. When it came to multitasking, all of the 16-bit applications were collectively treated with the same priority as a single, 32-bit application.
Today we have the same kind of thing going on with modern versions of Windows. 64-bit versions of Windows XP and Vista can run some types of 32-bit code, but this code must be kept separate from the 64-bit code.
So what does all of this have to do with Windows XP Mode? Well, Windows XP Mode is a first generation feature, so all it really allows us to do is to run a Windows XP based virtual machine. However, it also allows the Windows operating system to be greatly simplified.
Can you imagine how bloated and how prone to errors Windows 7 would be if Microsoft tried to make it natively fully backward compatible with Windows XP, but without using virtualization technology? I think that it is safe to say that Windows 7 would end up being a lot slower and less reliable than Vista.
By implementing Windows XP mode in the way that they have, Microsoft was able to design Windows 7 without having to build in special backward compatibility mechanisms.
To be fair, you are not going to see anything ground breaking in Windows 7. As we all know, Windows 7 was built on top of the Vista kernel. Having said that though, I believe Windows 7 is an extremely important architectural stepping stone for Microsoft. I think that Windows 8 will be a much lighter weight and efficient operating system. I also think that Microsoft will offer virtualization based plug-ins for backward compatibility.
In other words, I would expect Windows 8 to run only 64-bit code with absolutely no native support for 32-bit code. Those who need to run 32-bit code may be able to download a plug in that would allow them to do so, while the rest of us don’t have to worry about it. The same might be said for operating system compatibility. If someone needs to run applications that were designed for Windows XP, they might be able to download a Windows XP plug in.
Of course this is all speculation on my part, but Microsoft has laid the groundwork, and what I have described seems like the next logical step. Microsoft offers a product called Application Virtualization, which was previously known as SoftGrid. This product is designed to allow otherwise incompatible applications to be able to run side by side. Although Application Virtualization is an enterprise product, there is nothing stopping Microsoft from implementing similar functionality at the operating system level. Rather than using self contained virtualization for each individual application, Microsoft could offer virtualization modules that allow applications to run in the operating system for which they were originally designed.
Conclusion
So far I have told you what Windows XP Mode is going to be, and I have explained why I think that this is such an important development. There is a lot more that I want to tell you though. In Part 2 I will show you some of the cool new features that are going to be available to you as a part of the virtualization engine that Windows XP Mode is going to use.
Subscribe to:
Posts (Atom)